





























大数据和 NOSQL 连接器































ERP & CRM 连接器




















































营销和分析连接器



























协作连接器


































































电子商务连接器



















关系数据库连接器









































人工智能/机器学习创新需要灵活且可管控的数据架构
作者 Kevin Petrie, BARC 研究副总裁 | 2024 年 7 月 11 日
数据分析与所有技术学科一样,都是两种对立力量的故事:灵活性和治理。您需要灵活性来支持创新,但治理控制可以减轻创新的风险。
本博客探讨了这一原则对人工智能 (AI) 的影响,包括机器学习 (ML) 和生成式人工智能 (GenAI)。一方面,数据架构必须灵活地支持多种数据结构、集成样式和分析模型。另一方面,它还必须帮助管理使用情况,以降低与数据质量、隐私、知识产权 (IP)、偏见和可解释性相关的 AI/ML 风险。这枚硬币的两面都需要设计环境的数据架构师和管理环境的数据工程师的密切关注。
数据架构包含三层:基础设施、集成和访问。让我们从下图中自下而上探索每层中支持 AI/ML 的灵活元素
支持 AI/ML 的数据架构
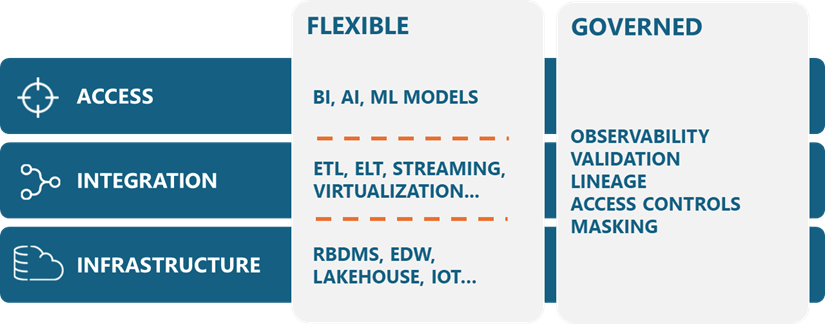
数据基础设施包括各种平台,用于存储、操作和检索多结构化数据集。数据团队正在使其基础设施越来越灵活,以处理新的数据类型和工作负载,因为 AI/ML 项目需要的不仅仅是传统的表格。他们可能需要来自物联网 (IoT) 传感器的半结构化日志来跟踪工厂零件的性能。他们可能需要客户对话的非结构化文本摘要或生物医学研究图像。
为了支持所有这些,数据团队正在实施诸如 Databricks 和 Snowflake 之类的 Lakehouse,以及传统数据库和数据仓库。随着 AI/ML 项目的发展,他们还采用了 Apache Iceberg 等开放表格式,以灵活地支持多种工具和处理引擎(Apache Spark、Trino 等)。
集成层使用这些基础设施资源来准备和交付为分析模型提供的数据。它必须具有灵活性,因为 AI/ML 项目需要的不仅仅是提取、转换和加载 (ETL) 定期批量操作表的传统管道。
例如,一些 ML 项目需要 ELT 管道来提取多源数据,然后在 Lakehouse 中合并、清理和重新格式化数据。同时,客户推荐引擎可能需要数据虚拟化,而欺诈预防可能需要实时流式传输。为了满足这些不同的需求,数据团队可以评估 CData 等提供商提供的灵活工具,这些工具使用所有这些样式来集成多结构数据:ETL、ELT、流式传输和虚拟化。
灵活访问
访问层是分析模型在训练或推理过程中检索和使用数据的地方。该层必须适应多种类型的分析模型,从简单的回归到聚类、异常检测、规范性 ML 和生成性 AI。这种灵活性需要开放的 API 以及与充满活力的商业和开源生态系统的轻松集成。该生态系统包括 PyTorch 等 AI/ML 库、Python 等编程语言以及 MLflow 等 MLOps 工具。数据团队可以通过避免使用限制互操作性的专有工具、平台或格式来实现这种灵活性。
灵活性带来了复杂性。复杂性增加了团队处理数据不当并与客户或监管机构发生冲突的风险。因此,数据团队必须对数据使用情况保持警惕的监督和控制。这给我们带来了
- 可观察性: 首先,数据团队必须观察架构如何处理和传递数据,例如通过监控延迟、正常运行时间等。
- 验证: 其次,他们必须验证数据是否完整、一致和准确,例如通过比较管道输入和输出。
- 世系: 数据团队还必须跟踪数据的沿袭。这有助于理解将非结构化对象(电子邮件、图像、音频文件等)转换为 GenAI 语言模型可以使用的向量嵌入所涉及的步骤。
- 访问控制: 数据团队必须使用基于角色的访问控制来限制用户操作,从而管理数据消费。
- 掩蔽: 最后,他们必须识别和屏蔽个人身份信息(PII),以确保客户隐私并遵守《通用数据保护条例》(GDPR)或《加州消费者隐私法案》(CCPA)等法规。
受控混乱
创新需要实验,而实验会带来混乱。从这个意义上说,数据架构师和数据工程师与幼儿园老师有很多共同之处!最有效的数据架构和教室提供了创新所需的灵活性,同时仍提供必要的规则和护栏。数据团队可以通过在整个数据环境中实施本博客中描述的元素来实现这一点:基础设施、集成和访问。
要了解有关该主题的更多信息,请查看我最近与企业数据平台 CData SVP Nick Golovin 一起举办的网络研讨会。
CData Software 是领先的数据访问和连接解决方案提供商。我们基于标准的连接器简化了数据访问,并使客户免于与本地或云数据库、SaaS、API、NoSQL 和大数据集成的复杂性。